아직 작성중..

※ General Network ※
1. LeNet (1998)
LeNet-1 (1990): CNN 개념 수립
LeNet-5 (1998):
- Average Pooling 사용 (Subsampling)
- 각 feature를 구하기 위해 이전 conv layer의 output feature 중 일부만을 사용. (다양한 조합의 feature들을 사용하여 global feature를 추출하고자함)

2. AlexNet (2012), [ILSVRC 2012]
- ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 2012에서 우승
- 네트워크를 크게 두 부분으로 나눈 뒤 GPU 병렬 연산 수행 (단순히 큰 네트워크를 처리하기 위함)
- ReLU와 Droout 사용

3. ZFNet (2013) [ILSVRC 2013]
- ILSVRC 2013에서 우승
- 학습된 Conv layer들의 시각화

Network In Network (ICLR14, arXiv:2013.12) https://arxiv.org/abs/1312.4400
- 1x1 Conv (point-wise conv) 최초 사용
- Global Average Pooling 최초 사용
4. GoogLeNet (Inception V1) (2014) [ILSVRC 2014]
- ILSVRC 2014에서 우승
- Inception Module을 구성
- 다양한 크기의 필터 사용
- 1x1 Conv (point-wise conv)를 사용하여 feature-wise 특징 추출(1x1)과 spatial-wise 특징 추출(?x?)을 분리하도록 함
https://datascienceschool.net/view-notebook/8d34d65bcced42ef84996b5d56321ba9/
5. VGG-16 (arXiv:2014.09) [ILSVRC 2014] https://arxiv.org/abs/1409.1556
- ILSVRC 2014에서 2위
- 3x3만을 이용한 간단한 구조 (5x5 => 3x3 두 번, 7x7 => 3x3 세 번)
6. ResNet (2015) [ILSVRC 2015]
- ILSVRC 2015에서 우승 (최초로 사람의 성능을 넘음)
- Skip Connection 개념 도입
- 4개의 ResBlock(Bottlenect) 사용
7. Inception V2, V3
- VGG-16의 3x3 conv 철학을 사용 (5x5를 3x3 두 개로 대체)
- 또한 3x3을 3x1과 1x3 두 개로 대체
- 참고 자료 : https://datascienceschool.net/view-notebook/8d34d65bcced42ef84996b5d56321ba9/
8. Inception V4, Inception-ResNet [ILSVRC 2016]
- ILSVRC 2016에서 우승
- 참고 자료 : https://datascienceschool.net/view-notebook/2537461edbac4ab081b8d7f2acb0d30d/
9. Xception (2016)
- Depth-wise Seperable Convolution
- ResNet의 Skip Connection 적용
- 참고 자료 : https://datascienceschool.net/view-notebook/0faaf59e0fcd455f92c1b9a1107958c4/
10. ResNet v2
- ResNet에서 activation function 위치를 변형
11. ResNeXt
- ResNet에서 Group Convolution 사용 (Cadinality 개념 사용)
12. Wide ResNet
- ResNet의 Bottleneck에서 채널의 크기를 늘림
13. DenseNet
- dense하게 skip connection 사용
14. NasNet (ICLR17, arXiv:2016.11) https://arxiv.org/abs/1611.01578
- AutoML의 architecture search를 통해 찾아낸 CNN
Residual Attention Network (CVPR17, arXiv:2017.04) https://arxiv.org/abs/1704.06904
- ResNet에 Self-Attention 사용
- spatial, channel 모두를 고려하여 attention
15. SENet (CVPR18, arXiv:2017.09) [ILSVRC 2017] https://arxiv.org/abs/1709.01507
- ILSVRC 2017에서 우승
- Residual Attention Network의 구조를 경량화함
- Squeeze와 Excitation을 통해 channel 별로 attention 수행 (spatial은 고려 안함)
16. BAM (BMVC18) / CBAM (ECCV18)
- SENet에서 spatial 까지 추가적으로 고려
17. MnasNet (CVPR19, arXiv:2018.07) https://arxiv.org/abs/1807.11626
- 기존 NasNet과 대비하여 적은 서치 스페이스 사용
- acc와 latency를 보상으로 사용
- 참고 자료 : https://www.youtube.com/watch?v=4uDZxefPd-I
17. EfficientNet (ICML19, arXiv:2019.05) https://arxiv.org/abs/1905.11946
- 모델의 Depth(레이어 수), Width(conv layer의 채널 수), Resolution(입력 영상 크기)를 모델의 크기를 결정하는 하이퍼파라미터로 보고, 제한된 크기에 따라 효과적인 모델을 찾아냄
- 적은 파라미터로 기존 sota 모델들에 비해 파라미터 대비 높은 성능을 이끌어냄
- mobile inverted bottleneck (MobileNet V2, Inverted Resdual Block)과 Squeeze and Excitation(SENet)을 혼용하여 기본 블럭으로 사용 (기존 MNas와 같은 서치 스페이스에서 architecture search로 찾아냄)
- 참고 자료 : https://www.youtube.com/watch?v=Vhz0quyvR7I
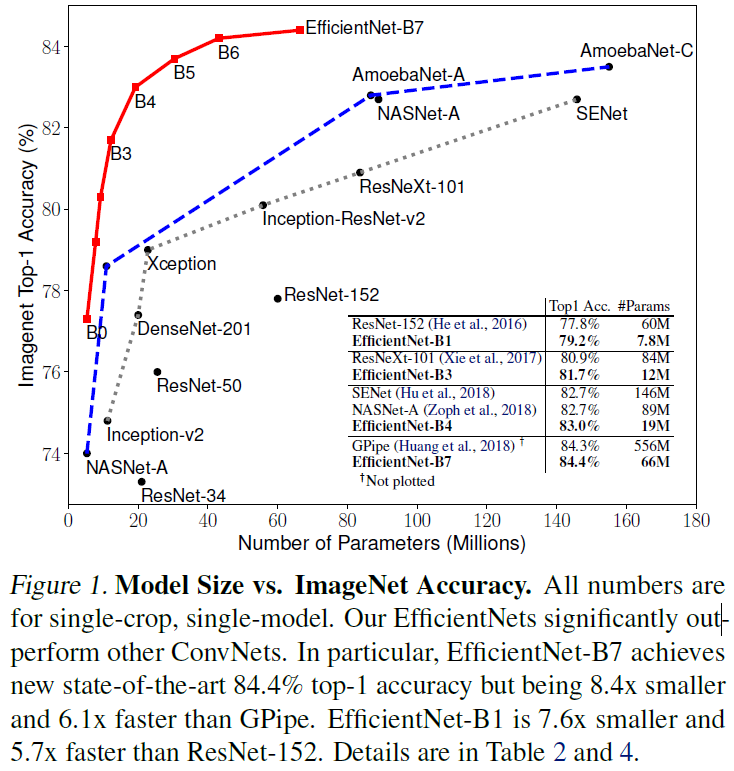
※ Efficient Network ※
1. SqueezeNet (2016)
- Fire Module 사용
- squeeze layer와 expand layer로 구성
- squeeze layer : 1x1 conv를 이용하여 차원 축소
- expand layer : 기존 resnet의 3x3를 일정 비율에 맞춰서 1x1로 대체
- 기존 Resnet의 각 module을 fire module로 대체
- AlexNet과 성능, 효율성 비교
2. MobileNet
- 1x1 conv 사용 (차원 축소 + 선형 결합의 연산 이점 목적)
- depth-wise separable convolution 사용 (Xception 영감)
- deep compression을 함께 사용하면 모델 크기를 크게 줄일 수 있음을 보임 (inception v3와 비교)
3. ShuffleNet (CVPR18)
- mobilenet 역시 sparse correlation matrix 문제가 발생
- grouped convolution을 통해서 위 문제를 해결하고자 함
- 하지만 grouped conv는 채널을 독립으로 나누기 때문에 서로 정보 교환이 없고 성능에 문제가 생김
- grouped conv 후에 channel을 섞는 아이디어 제안
- mobilenet보다 좋은 성능을 보임
4. MobileNet V2 (CVPR18)
- Inverted Residual Connection 사용 : resnet의 bottleneck에서 1x1로 피쳐를 줄이는게 아니라, 오히려 늘임
=> 이를 통해 residual connection이 있는 부분의 피처 수를 줄이고, bottleneck 내부에서 피쳐를 늘리고 depth-wise separable conv 수행 (피쳐를 늘리기 때문에 depth-wise separable conv가 피쳐 간의 정보를 보기 어렵다는 단점을 보완)
- MobileNet V1보다 성능과 효율을 높임. 또한 shuffle 보다 좀 더 좋은 성능을 보임
- MobileNet V1, ShuffleNet, NASNet 과 비교
5. SqueezeNext (2018)
-
6. ShuffleNet V2 (2018)
-
7. MobileNet V3 (ICCV19, arXiv:2019.05) https://arxiv.org/abs/1905.02244
- network architecture search(NAS) 활용
※ Backbone Network ※
FPN
-
DarkNet
-
※ Modified Convolution ※
Deonvolution (CVPR10) https://ieeexplore.ieee.org/document/5539957
-
Dilated Convolution
-
Deformable Convolution
-
Deformable Convolution V2
-
참고 자료
- https://www.youtube.com/watch?v=Dvi5_YC8Yts
- https://www.youtube.com/watch?v=ijvZsH4TlZc
- S. Bianco, R. Cadene, L. Celona and P. Napoletano, "Benchmark Analysis of Representative Deep Neural Network Architectures," in IEEE Access, vol. 6, pp. 64270-64277, 2018.
- https://kobiso.github.io/Computer-Vision-Leaderboard/imagenet
'이론 > 논문 리뷰' 카테고리의 다른 글
| AUGMIX: A SIMPLE DATA PROCESSING METHOD TO IMPROVE ROBUSTNESS AND UNCERTAINTY (0) | 2019.12.18 |
|---|